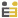EN
ENRAID เทคโนโลยีสูงสุดของการป้องกันความเสียหายของข้อมูลและความเร็วในฮาร์ดดิสก์
| Share | Tweet |
คำว่า RAID หรือ Redundant Array of Inexpensive Disks หรือการนำเอาฮาร์ดดิสก์หลายๆตัวมาเชื่อต่อกันผ่านตัว
Controller เพื่อจุดประสงค์ในการเพิ่มความจุ หรือความเร็วในการอ่าน/เขียนข้อมูล หลายๆคนที่ทำงานเกี่ยวกับด้าน File Sever,
Database Server หรือ Video, Image Editing คงจะรู้จักเป็นอย่างดี แต่สำหรับหลายๆคนที่ไม่ได้สัมผัสกับงานเหล่านี้
โดยตรง อาจจะเป็นการยากเมื่อถูกถามให้อธิบายความแตกต่างระหว่างของ RAID แต่ละชนิด ไล่ตั้งแต่ RAID 0,1,2,3,4,5,6,7,
10 และ 53 บทความนี้จะทำให้ท่านที่ไม่เคยรู้เรื่อง RAID เลยหรือรู้มาบ้างแต่ยังไม่ลึกซึ้งได้เข้าใจถึงการทำงาน, การนำไปใช้งาน
และข้อดีข้อเสียของ RAID แต่ละชนิดกัน
ทำไมถึงต้องมี RAID ?
….อย่างที่เราทราบกันดีแล้วว่ายิ่งขนาดของฮาร์ดดิสก์มีขนาดมากเท่าไหร่ ราคาของมันก็จะยิ่งมากขึ้นเท่านั้น ดังนั้นสำหรับงาน
ที่จำเป็นต้องใช้เก็บข้อมูลจำนวนมากอย่าง File หรือ Database Server ถ้าเราเลือกใช้ฮาร์ดดิสก์ความจุมากๆเพียงตัวเดียว
ในการเก็บข้อมูลหรือที่เรียกกันว่าเป็นการใช้ฮาร์ดดิสก์แบบ SLED หรือ Single Large Expensive Disk ราคาที่เราเสีย
ไปกับฮาร์ดดิสก์ตัวเดียวนั้น อาจจะไม่คุ้มค่าเท่ากับการใช้ฮาร์ดดิสก์ที่มีความจุต่ำกว่า (ซึ่งแน่นอนว่าราคาต้องถูกกว่าหลายเท่าด้วย)
นำมาต่อเพื่อให้ทำงานร่วมกันหรือที่เรียกกันว่าเป็นการใช้ฮาร์ดดิกส์แบบ RAID ซึ่งนอกจากความคุ้มค่าในแง่ของราคาแล้ว
ประสิทธิภาพในการทำงานแบบ RAID ยังมีมากกว่าแบบ SLED ด้วย ทั้งเรื่องของความเร็วในการเข้าถึงข้อมูล, ความน่าเชื่อถือ
ของข้อมูล (Reliability), การบริโภคกำลังงาน และความยืดหยุ่นในการขยาย ความจุในอนาคต (Scability) ซึ่งใน RAID แต่
ละชนิดก็จะตอบสนองต่อคุณสมบัติเหล่านี้ได้ต่างกัน ในหัวข้อต่อๆไปจะเป็นการกล่าวถึง RAID ชนิดต่างๆว่ามีการทำงานอย่างไร
และเหมาะกับการนำไปใช้งานด้านใดบ้าง
RAID 0 : Striped Disk Array without Fault Tolerance
 รูปที่ 1 | ..RAID ชนิดแรกที่จะพูดถึงก็คือ RAID 0 หรือ Striped Disk |
| RAID 1 : Disk Mirroring ..RAID 1 มีลักษณะโครงสร้างภายในตามชื่อของมัน ก็คือ |  รูปที่ 2 |
RAID 2 : Hamming Code ECC
.. RAID 2 เป็น RAID ชนิดแรกที่มีการใช้เทคโนโลยีในการตรวจจับความผิดพลาดของข้อมูล โดยอาศัยการเข้ารหัสแบบ Hamming Code ECC(Error Checking/Correction)
ก่อนที่จะพูดถึงวิธีการเข้ารหัสแบบ Hamming Code เราไปดูการตรวจจับความผิดพลาดของข้อมูลโดยการใช้บิต Parity
กันก่อน ข้อมูลที่ถูกส่งเข้ามาเก็บในฮาร์ดดิสก์ แต่ละตัวสำหรับ RAID 2 นั้น จะมีลักษณะเป็นขบวนบิตเลขฐานสอง ซึ่งแน่นอน
ในระหว่างการส่งผ่านข้อมูล โอกาสที่ข้อมูลที่เป็นขบวนบิตนี้จะผิดพลาดที่บิตใดบิตหนึ่งย่อมเกิดขึ้นได้ จึงได้มีการคิดวิธีเติมบิต
Parity เข้าไปที่ท้ายขบวนบิตข้อมูล(1 Word) โดยบิตที่เติมเข้าไปนี้จะเป็น “0″ หรือ “1″ ก็ขึ้นกับว่าเราจะใช้การตรวจจับเป็น
แบบ Even Parity หรือ Odd Parity ลองดูตัวอย่างต่อไปนี้
| ..สมมติขบวนบิตที่เข้ามาเป็นดังนี้ 1 0 0 1 0 0 1 ถ้าใช้ วิธี Even Parity ในการตรวจจับความผิดพลาด บิต Parity ที่จะถูกเติมเข้าไปต่อจากขบวนบิตข้อมูลจะต้อง ทำให้ผลรวมแบบเลขฐานสองของทุกบิต (รวมบิตที่เพิ่ม เข้าไปด้วย) มีค่าเท่ากับ “0″ (วิธีจำง่ายๆ 0 + 0 = 1, 1 + 1 = 0, 0 + 1 และ 1 + 0 = 1) จากตัวอย่างผลรวม ของขบวนบิตข้อมูล (ยังไม่รวมบิต Parity ) มีค่าเป็น 1+0+0+1+0+0+1 = 1 เพราะฉะนั้นบิต Parity ที่ถูก เติมเข้าไปก็คือ “1″ เพื่อทำให้ผลรวมของทุกบิตทั้งหมด จะกลายเป็น 1 0 0 1 0 0 1 1 |  รูปที่ 3 |
..ส่วนในกรณีของ Odd Parity บิต Parity ที่จะถูกเติมเข้าไปจะต้องเข้าไปทำให้ผลรวมของทุกบิต (รวมบิต Parity ด้วย)
มีค่าเป็น “1″ และเมื่อปลายทางได้รับข้อมูลที่ผ่านการเติมบิต Parity มาแล้วก็จะสามารถตรวจสอบได้ว่าข้อมูลที่ได้รับมาผิดพลาด
หรือไม่ ยกตัวอย่างสมมติว่าเกิดผิดพลาดขึ้นที่บิตที่ 3 ทำให้ข้อมูลที่ผ่านการทำ Even Parity มาแล้วผิดพลาดเป็น 1 0 1 1 0 0
1 1 ทางฝั่งรับจะรู้ได้ทันทีว่าข้อมูลนี้ผิดพลาด โดยดูจากผลบวกของทุกบิต 1+0+1+1+0+0+1+1 = 1 ซึ่งขัดกับการทำ Even
Parity ที่ผลรวมของทุกบิตจะต้องเป็น “0″ ทางฝั่งรับก็อาจจะส่งสัญญาณตอบกลับไปที่ฝั่งส่ง ให้ทำการส่งข้อมูลมาใหม่อีกครั้ง
 รูปที่ 4 | … สำหรับวิธีเติมบิต Parity ที่ได้พูดไปข้างต้นนี้ ยังมีข้อเสียอยู่ตรงที่ถ้าเกิดบิตข้อมูลเกิดการผิดพลาด พร้อมกัน 2 บิต ทางฝั่งรับจะไม่สามารถตรวจจับความ ผิดพลาดได้เลยอย่างเช่นสมมติว่าบิตที่ 2 และ 3 เกิด การผิดพลาดเป็น 1 1 1 1 0 0 1 1 ผลรวมของบิตทั้ง หมดก็ยังเป็น “0″ อยู่ดี แม้จะเกิดความผิดพลาดขึ้น และข้อเสียอีกประการก็คือวิธีเติมบิต Parity นี้ ทำได้ เฉพาะตรวจจับความผิดพลาดได้เท่านั้น |
..แต่ไม่สามารถระบุได้ว่าบิตใดเกิดความผิดพลาดขึ้น จึงทำการแก้ไขข้อมูลให้ถูกต้องไม่ได้ ด้วยเหตุนี้จึงต้องมีการคิดค้นวิธีที่จะ
เข้ามาแก้ปัญหาเหล่านี้ วิธีที่ว่าก็คือ วิธีการเข้ารหัสข้อมูล ซึ่งมีอยู่หลายวิธีด้วยกัน แต่ที่นำมาใช้ใน RAID 2 จะเป็นวิธีการเข้ารหัส
แบบ Hamming Code
หลักการของการเข้ารหัสก็คือ ขบวนบิตข้อมูลจำนวน k บิต จะถูกเข้ารหัสให้กลายเป็นคำรหัส (Code Word) ที่มีความยาว
n บิต โดยจะมีการเติมบิตที่ใช้ในการตรวจสอบ (Check Bits) n - k บิตต่อท้ายบิตข้อมูล โดยบิตที่ใช้ในการตรวจสอบนี้จะมี
ความสัมพันธ์กับบิตข้อมูลด้วย ส่วนจะสัมพันธ์ในรูปแบบไหนก็ขึ้นอยู่กับว่าใช้การเข้ารหัสแบบใด ในส่วนของการเข้ารหัสแบบ
Hamming Code นี้จะอาศัยการสร้างบิตตรวจสอบจากวิธีการดังนี้
ในการเข้ารหัสแบบ Hamming Code จะใช้ขบวนบิตข่าวสาร 4 บิต และจะมีการเติมบิตที่ใช้ในการตรวจสอบเข้าไป 3 บิต
รวมเป็น 7 บิต สมมติให้ s1 - s4 แทนขบวนบิตข้อมูล และ t5-t7 แทนบิตตรวจสอบ ดังนั้นขบวนบิตทั้งหมดหลังจากการทำการ
เข้ารหัสแล้วจะเป็นดังนี้ s1-s2-s3-s4-t5-t6-t7 บิต t5-t7 หาได้จากวิธีในรูปที่ 3
s | t | s | t | s | t | s | t |
0000 | 0000000 | 0100 | 0100110 | 1000 | 1000101 | 1100 | 1100011 |
0001 | 0001011 | 0101 | 0101101 | 1001 | 1001110 | 1101 | 1101000 |
0010 | 0010111 | 0110 | 0110001 | 1010 | 1010010 | 1110 | 1110100 |
0011 | 0011100 | 0111 | 0111010 | 1011 | 1011001 | 1111 | 1111111 |
..หลักการหาก็คือว่าทั้ง t5, t6 และt7 จะต้องมีค่าที่ทำให้ผลรวมของบิตในแต่ละวงกลมเป็น Even(”0″) อย่างตัวอย่างใน
รูปที่ 3-b ถ้า s = 1 0 0 0 บิต t5 ก็ต้องเป็นบิตที่ทำให้ผลรวมของ s1-s2-s3-t5 เป็น “0″ ดังนั้น t5 จึงเป็นบิต “1″ ก็ทำใน
ลักษณะเดียวกัน ดังนั้นขบวนบิตหลังจากผ่านการเข้ารหัสก็จะเป็น 1 0 0 0 1 0 1 ตารางที่ 1 แสดงขบวนบิตข้อมูลที่เป็นไป
ได้ทั้งหมดกับขบวนบิตหลังผ่านการเข้ารหัส
..สำหรับการเข้ารหัสโดยวิธี Hammimg Code นี้ จะได้เปรียบวิธีเติมบิต Parity ตรงที่ทางฝั่งรับสามารถระบุได้ว่าบิต
ใดเกิดความผิดพลาดขึ้น จึงทำให้เราสามารถแก้ไขความผิดพลาดที่เกิดขึ้นได้ แต่มีข้อแม้ว่าข้อผิดพลาดนั้นต้องมีเพียงบิตเดียว และต้องไม่ใช่บิต s3 ลองพิจารณาดูรูปที่ 4 สมมติว่าใช้ขบวนบิตที่ผ่านการเข้ารหัสมาแล้วเหมือนตัวอย่างที่แล้วคือ 1 0 0 0 1
0 1 แล้วเกิดความผิดพลาดที่บิต s2 ทำให้ข้อมูลเปลี่ยนเป็น 1 0 1 0 1 0 1 หรือเขียนเป็นไดอะแกรมได้ตามรูปที่ 4a จะเห็นได้
ว่าจะมีเฉพาะวงกลมเส้นประเท่านั้นไม่เป็นไปตาม Even Parity ดังนั้นบิตที่เป็นไปได้ที่จะทำให้เกิดความผิดพลาดกับวงกลม
ทั้งสองวงก็คือบิต s3 = 0 และ s2 = 1 แต่เราจะตัดการพิจารณาบิต s3 ออกไปเพราะบิต s3 อยู่ในอาณาเขตของวงกลมเส้น
ทึบด้วย สาเหตุก็เนื่องมาจากว่าถ้าบิต s3 เกิดความผิดพลาด มันก็จะไปส่งผลกระทบต่อ Even Parity ของวงกลมเส้นทึบด้วย
จึงเหลือบิตให้พิจารณาเพียงบิตเดียวคือ s2 เพราะฉะนั้นทางฝั่งรับก็จะรู้ได้ทันทีว่าบิต s2 เป็นบิตผิดพลาด ก็จะมีการแก้ไขเกิด
ขึ้นโดยการกลับบิตจาก “1″ เป็น “0″ ส่วนรูปที่ 4b บิตที่ผิดพลาดจะเป็นบิต t5 ซึ่งเป็นการตรวจสอบที่เพิ่มเข้าไป จากรูปจะเห็น
ได้ว่า ถ้าบิตตรวจสอบเกิดความผิดพลาด ทางฝั่งรับจะรู้ได้ทันทีว่าเป็นบิตไหน เพราะวงกลมเส้นประจะเกิดขึ้นแค่วงเดียว และ
บิต s1, s2 และ s3 ก็อยู่ในอาณาเขตของวงกลมทึบด้วย ดังนั้นจึงมีเพียงบิตเดียวที่อยู่ในวงกลมเส้นประล้วนๆนั้นคือบิต t5
ในรูปที่ 4c จะเป็นไดอะแกรมแสดงจุดบอดของวิธี Hamming Code เพราะถ้าบิตตรงกลางวงกลม บิต s3 เกิดผิดพลาดขึ้น
ทางฝั่งรับจะไม่มีทางรู้ได้เลยว่าบิตใดผิดพลาด เพราะวงกลมทั้งสามวงเป็นเส้นประหมด โดยทางฝั่งรับจะตีความว่าข้อมูล
ที่ได้รับเกิดการผิดพลาด แต่จะไม่มีการแก้ไขใดๆ เกิดขึ้นต้องให้ทางฝั่งส่ง ทำการส่งข้อมูลมาใหม่เท่านั้น
 |
..ทางฝั่งรับข้อมูลจะมีตารางข้อมูลแบบตารางที่ 1 เอาไว้เพื่อถอดรหัสเอาข้อมูลออกมา เช่นเดียวกับทางฝั่งส่ง ใน RAID 2 นั้น
ฮาร์ดดิสก์แต่ละตัวจะเก็บข้อมูลที่เข้ามาทีละบิตๆ ดูรูปที่ 5 A0-A3 จะแทนข้อมูล 1 word โดยทั้ง 4 บิตนี้จะผ่านการเข้ารหัสแบบ
Hamming Code โดยการเติมบิตตรวจสอบ ECC/Ax, ECC/Ay และ ECC/Az เข้าไป ทำให้ RAID 2 มีความสามารถ
ในการแก้ไขความผิดพลาดได้ แต่ข้อเสียที่เราเห็นได้อย่างชัดเจนของ RAID 2 ก็คือการที่มันต้องใช้ฮาร์ดดิสก์ เพื่อเก็บบิตตรวจ
สอบเกือบๆเท่ากับจำนวนฮาร์ดดิสก์ที่ใช้เก็บข้อมูล เพราะยิ่งขนาด word ของข้อมูลเล็กเท่าไหร่สัดส่วนระหว่างฮาร์ดดิสก์ทั้งสอง
ชนิดก็ยิ่งเกือบจะเท่าๆกัน ดูจากรูปที่ 5 นั่นก็หมายความว่า เราต้องเสียค่าใช้จ่ายอีกประมาณเกือบเท่าตัวในการเก็บบิตตรวจสอบ
ซึ่งเป็นเรื่องที่ค่อนข้างสิ้นเปลืองทีเดียว
RAID 3 : Pararell Transfer with Parity
..สำหรับ RAID 3 นั้นตามโครงสร้างจะมีลักษณะการต่อฮาร์ดดิสก์เป็นแบบ Stripe เช่นเดียวกับ RAID 0 โดยข้อมูลที่
เข้ามาแต่ละครั้งจะถูกแยกเก็บไว้ที่ฮาร์ดดิสก์แต่ละตัว ส่วนแต่ละตัวจะเก็บข้อมูลกี่บิตหรือกี่ไบต์ก็ขึ้นอยู่ที่การกำหนด(ขอเรียกข้อ
มูลที่เก็บอยู่ใน A0, A1, A2,
ตามรูปที่ 6 ว่าเป็น 1 word) จากรูปที่ 6 ข้อมูลที่เข้ามาก็จะถูกแบ่งย่อยเพื่อเก็บไว้ที่ A0, A1,
A2, A3, B0,
จนกว่าจะเก็บข้อมูลได้หมด ลักษณะการต่อฮาร์ดดิสก์ตามรูปที่ 6 เป็นการต่อที่เรียกว่า 4+1 คือมีฮาร์ดดิสก์ที่ไว้
เก็บข้อมูล 4 ตัว และเก็บ Parity ที่ได้จากการคำนวณทางคณิตศาสตร์ของข้อมูลในแถวๆนั้น (ดูตามรูปที่ 6 A Parity จะเป็น
Parity ของข้อมูล A0-A3) อีก 1 ตัว
การคำนวณหา Parity นั้นจะอาศัยวิธีการทางคณิตศาสตร์ง่ายๆ คือการนำเอาลอจิก XOR เข้ามาช่วย โดยเงื่อนไขของการ
ทำ XOR เป็นดังที่แสดงในตารางที่ 2
XOR Example | ||||
A XOR B | Result | |||
0 | 0 | 0 | ||
1 | 0 | 1 | ||
0 | 1 | 1 | ||
1 | 1 | 0 | ||
ตารางที่ 2 | ||||
จากเหตุผลข้างต้นจึงมีการนำลอจิก XOR มาสร้าง Parity ขึ้นมาโดย A Parity = A0 XOR A1 XOR A2 XOR A3
(ในส่วนของแถว B, C และ D ก็เป็นในทำนองเดียวกัน)
และถ้าข้อมูลจากฮาร์ดดิสก์ตัวใดเกิดสูญหาย เราก็สามารถสร้าง word ข้อมูลนั้นขึ้นมาใหม่ได้ด้วยการนำ A Parity มา XOR
กับ word ข้อมูลที่ยังเหลืออยู่ สมมติ word ข้อมูลเป็นดังนี้ A0= 1010, A1= 0011, A2 = 0001 และ A3 = 1000 ดังนั้น A
Parity จะมีค่าเท่ากับ 0000 และสมมติให้ข้อมูล A2 เกิดสูญหายอันเนื่องมาจากฮาร์ดดิสก์ตัวที่ 3 เกิดปัญหาเราจะสร้างข้อมูล A2
กลับคืนมาได้โดยนำ A Parity 0000 XOR กับ word ข้อมูลที่ยังเหลืออยู่ซึ่งก็คือ A0, A1 และ A3 จะได้ผลลัพธ์คือ 0001 ซึ่ง
ก็คือ word A2 นั่นเอง
 |
รูปที่ 6 |
แม้ว่า RAID 3 จะมีข้อดีในการอ่านและเขียนข้อมูลได้อย่างรวดเร็ว เพราะมีลักษณะการต่อฮาร์ดดิสก์เป็นแบบ Stripe และ
ใช้ฮาร์ดดิสก์ในการเก็บ Parity เพียงแค่ตัวเดียวเท่านั้น แต่ถ้านำ RAID 3 ไปใช้กับงานที่ข้อมูลที่มีการผ่านเข้าออกเป็นจำนวนเล็ก
น้อยในแต่ละครั้ง แต่ลักษณะการเขียนข้อมูลมีการกระจายไปทั่วทั้งฮาร์ดดิสก์ จะส่งผลให้เกิดเวลาคอขวดขึ้นที่ฮาร์ดดิสก์ที่เก็บ
Parity เพราะไม่ว่าข้อมูลจะไปปรากฏอยู่ในกลุ่มของ word ข้อมูลแถวไหน RAID 3 ก็จะมีการสร้าง Parity ขึ้นมาตลอด ซึ่งแม้
ว่าข้อมูลเราจะมีขนาดเล็ก แต่ RAID 3 ก็จำเป็นต้องเสียเวลาไปสร้าง Parity ขึ้นมาตลอด ซึ่งแม้ว่าข้อมูลเราจะมีขนาดเล็ก แต่
RAID 3 ก็จำเป็นต้องเสียเวลาไปสร้าง Parity ขึ้นในทุกๆแถวที่ข้อมูลนั้นไปอยู่ ยิ่งข้อมูลกระจายไปอยู่แถวต่างๆมากขึ้น จำนวน
Parity ก็จะมากขึ้นตามและในแต่ละครั้งของการที่จะเขียนข้อมูลใหม่ลงไป RAID 3 จำเป็นจะต้องรอให้ Parity ถูกเขียนให้เสร็จ
ก่อนที่ข้อมูล word ต่อไปจะถูกเขียน (เป็นลักษณะของการทำงานแบบ Synchronous) ยกตัวอย่าง ตามรูปที่ 6 ถ้าเราต้องการ
เขียนข้อมูลลงที่ word A0 ฮาร์ดดิสก์ที่ต้องใช้ในการเขียนจะมีอยู่ 2 ตัวคือฮาร์ดดิสก์ตัวที่ 1 และฮาร์ดดิสก์ตัวที่ 5 จะเห็นได้ว่า
ก่อนที่ word B2 จะถูกเขียนมันจะต้องรอจนกว่าฮาร์ดดิสก์ตัวที่ 5 จัดการ Parity ของ word A1 ให้เสร็จก่อน เวลาที่เกิดนี้แหละ
ที่เป็นเวลาคอขวด ยิ่งมีการกระจายการเขียนข้อมูลไปหลายๆแถวเมื่อใด ก็ยิ่งต้องเสียเวลารอมากขึ้นเท่านั้น ฉะนั้นงานที่เหมาะจะเอา
RAID 3 ไปใช้งานก็ควรจะเป็นงานที่ต้องการการอ่านข้อมูลจำนวนมากในเวลารวดเร็ว เพราะการอ่านจะไม่ไปยุ่งกับส่วนของ
Parity ถ้าข้อมูลไม่สูญหาย เช่นงานด้านการผลิตหรือตัดต่อ Video
RAID 4 : Independent Data Disks with Shared Parity Disk
หลักการทำงานของ RAID 4 จะเหมือนกับ RAID 3 แทบทุกประการจะต่างกันก็ตรงที่ แต่ละ Word ข้อมูลใน RAID 3 นั้น
จะมีขนาดกี่บิตหรือกี่ไบต์ก็อยู่กับการกำหนด แต่ใน RAID 4 Word ข้อมูล จะเก็บในรูป Block ข้อมูล (1 Sector) แทน เพราะ
ฮาร์ดดิสก์ส่วนใหญ่จะอ่านข้อมูลแต่ละครั้งจะอยู่ในรูปของ Block โดยขนาดของ Block จะมีตั้งแต่ 512 Byte ถึง 8 KB ขึ้นกับ
ระบบปฏิบัติการที่ใช้ รูปที่ 7 แสดงการทำงานของ RAID 4 ในการเปลี่ยนมาใช้การเก็บข้อมูลเป็น Block นี้ จะช่วยให้จำนวนครั้ง
ในการเก็บข้อมูลและกระบวนการเปรียบเทียบ XOR น้อยลง ซึ่งจะส่งผลให้เวลาในการกู้หรือเก็บข้อมูลสั้นลงตามไปด้วย อย่างไร
ก็ตามเวลาคอขวดอย่างที่เกิดใน RAID 3 ก็ยังคงมีอยู่เช่นเดิม
 |
รูปที่ 7 |
RAID 5 : Independent Data Disk with Distributed Parity Blocks
RAID 5 จะมีการเก็บข้อมูลเป็น Block เช่นเดียวกับใน RAID 4 ข้อเสียที่สำคัญที่สุดของ RAID 3 และ 4 ก็คือ เรื่องเวลา
คอขวดที่เกิด เนื่องจากการเขียนส่วน Parity ดังที่ได้ยกตัวอย่างไปแล้ว สำหรับ RAID 5 จะมีการแก้ไขปัญหานี้โดยการ นำเอา
ส่วนของ Parity Block ไปกระจายอยู่ในฮาร์ดดิสก์แต่ละตัว ไม่แยกมาเก็บโดดๆเหมือนใน RAID 3 การกระทำเช่นนี้จะลดเวลา
คอขวดได้อย่างไร จะขอเปรียบเทียบกับตัวอย่างที่ได้ยกไปในหัวข้อ RAID 3 นั่นคือการเขียนข้อมูลที่ Word A0 และ B1 ใน
กรณีของ RAID 5 การเขียนข้อมูลลง Word A0 จะใช้ฮาร์ดดิสก์ 2 ตัวคือ ตัวที่ 1 และ 5 ส่วน Word B1 จะใช้ตัวที่ 2 และ 4
จะเห็นได้ว่าเราไม่ต้องไปเสียเวลารอให้ RAID 5 ทำส่วนของ Parity ให้เสร็จก่อนเหมือนอย่าง RAID 3 แล้ว เพราะเราสามารถ
เขียนทั้ง Word A0 และ B1 ไปได้พร้อมๆกันเลย นี่จึงเป็นที่มาของการกระจายส่วนของ Parity Block ให้อยู่ในทุกๆฮาร์ดดิสก์
 |
รูปที่ 8 |
อย่างไรก็ตามการมี Parity Block อย่างใน RAID 3, 4 หรือ 5 จะส่งผลกระทบต่อการเขียนข้อมูลค่อนข้างมากเช่นกัน เพราะ
ถ้าเปรียบเทียบระหว่าง RAID 5 กับ RAID 0 จะทำได้ง่าย เพราะจะเป็นการเขียนลงฮาร์ดดิสก์เพียงตัวเดียว แต่ในกรณีของ RAID
5 จำนวน Block ที่ต่ำสุดที่จะถูกเขียนจะไม่ใช่ 1 Block แล้ว อย่างในรูปที่ 8 การเขียนข้อมูลลงใน Block B2 ข้อมูลเก่าที่อยู่ใน
Block B 2 และ Parity Block 2 จะต้องถูกอ่านขึ้นมาก่อน แล้วนำมาเก็บไว้ในหน่วยความจำแคช แล้วนำข้อมูลใน Block B2
มาทำการ XOR กับ Parity ผลที่ได้ก็คือข้อมูลของ Block ที่เหลือในแถวนั้นที่ได้ถูกนำมา XOR กันแล้ว หลังจากอ่านข้อมูลเก่า
เสร็จ ข้อมูลใหม่ก็จะถูกเขียนลงไปที่ Block B2 จากนั้นก็จะมีการคำนวณ Parity ใหม่อีกครั้ง โดยการนำเอาข้อมูลใหม่ไป XOR
กับผลที่ได้จากการอ่านในครั้งแรกก่อน แล้วจึงจะมีการเขียน Parity ลงใน Parity Block จะเห็นได้ว่าต้องใช้กระบวนการอ่าน
และเขียนถึง 4 ครั้ง กับการเขียนข้อมูลเพียงบิตเดียว
ดังนั้นจึงมีการนำหน่วยความจำแคชมาใช้กับตัว Controller RAID 5 เพื่อช่วยเพิ่มความเร็วในการเขียนข้อมูลให้เร็วมากขึ้น
(จาก 5-12 msec ลดเหลือ 0.5 msec) โดยมีขนาดประมาณ 64-256 MB การนำหน่วยความแคชมาใช้นี้ส่งผลให้ประสิทธิภาพ
ในการทำงานของ RAID 5 ดีกว่า RAID 0 เสียอีก
นอกจากนั้น RAID 5 ยังมาพร้อมกับคุณสมบัติ “Hot Swap” นั่นคือสามารถมีการสลับสับเปลี่ยนข้อมูลระหว่างฮาร์ดดิสก์
ที่ดีกับฮาร์ดดิสก์ที่เสียได้ ขณะที่ระบบกำลังทำงานอยู่ สาเหตุก็เพราะ RAID 5 สามารถสร้างข้อมูลที่หายไปกลับมาใหม่ได้โดยอา
ศัย Parity Block ที่เก็บอยู่ในฮาร์ดดิสก์ตัวอื่นนั่นเอง สำหรับงานที่เหมาะกับการนำ RAID 5 ไปใช้งานก็ได้แก่งานที่ไม่ต้องการ
ปริมาณการเขียนข้อมูลมากนัก แต่จะถูกอ่านข้อมูลมากกว่า และข้อมูลที่เก็บก็มีขนาดใหญ่มากเกินกว่าที่จะลงทุนทำที่ฮาร์ดดิสก์เงาเพื่อ
แบ๊คอัพข้อมูลอย่างใน RAID 1 เช่นงานจำพวก File Server, Database Server, WWW, E-mail หรือ News Server
หรือ Intranet Servers
RAID 6 : Independent Data Disks with Two Independent Distributed Parity Schemes
. RAID 6 นั้นจะมีพื้นฐานการทำงานเหมือนกับ RAID 5 แทบทุกประการ เพียงแต่ว่า RAID 6 นั้นมีการเพิ่ม Fault Tolerance
ให้มากขึ้นกว่า RAID 5 เท่านั้น วิธีการก็คือการเพิ่ม Parity Block เข้าไปอีก 1 ชุด ดังรูปที่ 9 เพื่อยอมให้เราสามารถทำการสลับ
เปลี่ยนฮาร์ดดิสก์ได้พร้อมกัน 2 ตัว ในยามที่เกิดเหตุเสียขึ้นพร้อมกัน และด้วยการที่มี Parity Block เพิ่มขึ้นนี้จึงส่งผลให้การเขียน
ข้อมูลช้ายิ่งกว่าใน RAID 5 อีก นอกจากนั้นการเพิ่มจำนวน Parity Block ก็ยังส่งผลให้จำนวนฮาร์ดดิสก์ที่ใช้เพิ่มขึ้นอีกด้วย โดย
สมมติว่าเราใช้ฮาร์ดดิสก์สำหรับเก็บข้อมูล n ตัว เราต้องจัดหาฮาร์ดดิสก์มาสำหรับการต่อแบบ RAID 6 นี้ n+2 ตัว ดูรูปที่ 9
ประกอบ ดังนั้นงานที่จะนำ RAID 6 ไปใช้ก็ควรจะเป็นงานประเภท Mission Critical หรืองานที่ต้องการเสถียรภาพของข้อมูล
ในระดับสุดยอดจริงๆถึงจะคุ้มค่าต่อการลงทุน
 |
รูปที่ 9 |
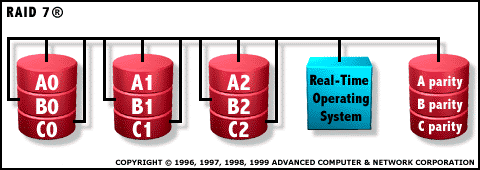
RAID 7 : Optimized Asychronous for high I/O Rate + High Data Transfer Rates
RAID 7 นั้นโดยพื้นฐานแล้วก็คือ RAID 4 ที่มีการเพิ่มคุณสมบัติหนึ่งเข้าไป คุณสมบัติที่ว่าก็คือการส่งข้อมูลเข้า และออกจาก
ฮาร์ดดิสก์นั้นจะเป็นในลักษณะ Asynchronous และจะถูกควบคุมอย่างอิสระ นอกจากนั้นการอ่าน หรือการเขียนทุกๆครั้งจะถูก
ส่งระบบบัสความเร็วสูงที่มีชื่อว่า “X-Bus” การทำงานในลักษณะ Asynchronous นั้นหมายความว่าฮาร์ดดิสก์แต่ละตัวจะ
ทำงานอย่างเป็นอิสระต่อกัน นั่นคือฮาร์ดดิสก์หนึ่งๆ ไม่จำเป็นที่จะต้องรอให้ฮาร์ดดิสก์อีกตัวเสร็จสิ้นการเขียนก่อนตัวมันถึงจะทำ
การเขียนต่อได้อย่างใน RAID 4 อีกต่อไป RAID 7 อาศัยหลักการที่ใช้หน่วยความจำแคชหลายระดับและหลายๆ Bank ในตัว Controller เพื่อแยกการทำงานต่างๆออกจากกัน ที่ตัว RAID 7 จะมี Real-Time Operating System ที่ฝังอยู่ภายใน
Array Control Processer คอยทำหน้าที่ควบคุมการทำงาน Asyschronous ที่เกิดขึ้นบนเส้นทางการสื่อสาร
 |
รูปที่ 10 |
นอกจากนั้น OS ที่ว่านี้ยังทำหน้าที่ควบคุมการทำงานของ Bus control Logic, High Speed Bus controller Logic
, Cache Control Logic, การสร้าง Parity และการตรวจสอบ Control Logic โดยจะมีทางเชื่อมต่อระหว่าง OS ของเครื่อง
Host กับ OS ที่ฝังอยู่ในอุปกรณ์ RAID 7 ทางเชื่อมต่อนี้มีจุดประสงค์เพื่อใช้เส้นทางให้ Host สามารถควบคุม RAID 7 ให้ทำ
งานได้ตามต้องการ เพราะฉะนั้นบริษัทผู้ผลิต Host จึงสามารถเขียนหรือแก้ไขโค้ดการทำงานของ OS ที่ฝังอยู่ใน RAID 7 ได้
ซึ่งก็จะช่วยให้ผู้ผลิตสามารถลดค่าใช้จ่ายในการพัฒนาคุณสมบัติการทำงานใหม่ๆให้กับ RAID 7 ได้มากทีเดียว
RAID 7 สามารถเชื่อมต่อได้มากถึง 12 Host Interfaces และมากถึง 48 ไดร์ฟ และด้วยคุณสมบัติหลายๆอย่างของ RAID
7 ส่งผลให้ RAID 7 มีประสิทธิภาพในการเขียนข้อมูลมากกว่า RAID ชนิดอื่นๆกว่า 1.5 ถึง 6 เท่า และด้วยประสิทธิภาพที่สูงขึ้น
ส่งผลให้ราคาของ RAID 7 นั้นสูงตามไปด้วย และเนื่องจาก RAID 7 ซึ่งเป็นลิขสิทธิ์ของบริษัท Storage Computer Corp.
นั้นมีการทำงานที่ค่อนข้างจะซับซ้อนอยู่พอสมควร ทางบริษัทจึงไม่อนุญาตให้ลูกค้าแก้ไขสิ่งใดๆ กับเครื่องเลย และการรับประกัน
ก็ยังมีช่วงเวลาที่สั้นเกินไป
RAID 10 : Mirroring with striped subsets
RAID 10 ความจริงแล้วก็คือการรวมเอาโครงสร้างของ RAID 0 และ 1 เข้าด้วยกันนั่นเอง การรวมกันนี้จะส่งผลให้การเข้า
ถึงข้อมูลจะรวดเร็วขึ้น (คุณสมบัติของ RAID 0) ในขณะเดียวกันก็จะมีการแบ๊คอัพข้อมูลไปด้วยตลอดเวลา (คุณสมบัติของ RAID
1 ) ลักษณะของโครงสร้าง RAID 10 จะเป็นดังรูปที่ 11 นั่นคือ ฮาร์ดดิสก์แต่ละตัวก็จะมีฮาร์ดดิสก์ “เงา” อยู่คู่กัน โดยข้อมูลของ
ฮาร์ดดิสก์แต่ละคู่ก็จะส่งออกมาในลักษณะขนานกัน และจากโครงสร้างของ RAID 10 นี้ จึงมีชื่อเรียก RAID 10 อีกอย่างว่าเป็น
RAID ที่มีลักษณะ 2 มิติ
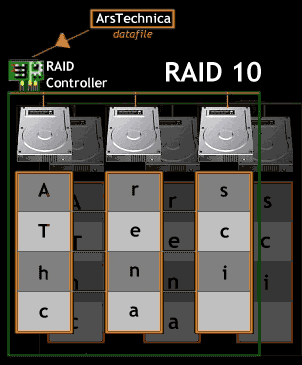 | และจากการที่ RAID 10 ต้องมีฮาร์ดดิสก์ “เงา” คู่กับฮาร์ดดิสก์หลักทุกตัว ก็ทำให้การเพิ่มจำนวนฮาร์ดดิสก์ในอนาคตทำได้ค่อนข้างลำบาก เพราะยิ่งเราเพิ่มจำนวนฮาร์ดดิสก์เก็บข้อมูลมากขึ้นเท่าใด เราก็ต้องเพิ่มฮาร์ดดิสก์แบ๊คอัพมากขึ้นเป็นเงาตามตัว เพราะฉะนั้นงานที่จะนำ RAID 10 ไปใช้จึงควรเป็นงานประเภท Database Server ที่ต้องการประสิทธิภาพในการอ่าน/เขียนข้อมูลสูงๆ และมี Full Tolerance ดี แต่มีความจุข้อมูลไม่สูงมากนัก และไม่ต้องการคุณสมบัติด้าน Scalability มากเท่าใด | |
รูปที่ 11 |
RAID 53 : High I/O + Data Transfer Performance
 |
รูปที่ 12 |
RAID 53 นั้น ถ้าพิจารณาจากพื้นฐานการทำงานแล้วน่าที่จะเรียกว่า RAID 30 มากกว่า เพราะมันเป็นการนำเอาการจัดเรียงแบบ
Stripe อย่างใน RAID 0 มาใช้ โดยแต่ละ Segment ข้อมูลจะใช้โครงสร้างแบบ RAID 3 ดูรูปที่ 12 ประกอบ ดังนั้น RAID 53
จึงมีอัตราการส่งข้อมูลสูงอันเนื่องมาจากโครงสร้าง RAID 0 และมี Fault Tolerance ในระดับเดียวกับ RAID 3 ด้วยคุณสมบัติ
ดังกล่าว RAID 53 จึงมักถูกนำไปใช้กับงานที่เคยใช้กับ RAID 3 มาก่อน แต่ต้องการเพิ่มความเร็วในการส่งผ่านข้อมูลให้มากขึ้น แต่
ต้องตระหนักเสมอว่า RAID 53 นี้ยังคงมีรูปแบบการทำงานแบบ Synchronous ดังนั้นปัญหาเรื่องเวลาคอขวดก็จะยังคงมีอยู่
เหมือนกับ RAID 3
ขอต่ออีกหน่อยน่ะ สำหรับผมแล้วผมเคยลองใช้ Mode 0 (Stripe)น่ะ ก็ใช้การ์ด MS-6915 (PDC20265) Mo เป็น RAIDผมว่า เยี่ยมเลยครับ ระบบเร็วและลื่นขึ้นมากเลยครับ ไม่หนึดหรือต้องหยุดรอการ อ่าน/เขียน ข้อมูลของ Harddisk ให้เสียอารมณ์แต่ก็ใช่ว่ายิ่ง Harddisk หลายตัวความเร็วที่ได้จะเพิ่มตามนั้นน่ะ เช่นใช้ 2 ตัวก็น่าจะเพิ่มขึ้น 2 เท่า(ของความเร็วตัวที่ช้าที่สุด) แต่ว่าที่ได้จริงๆก็ประมาณ 1.75 - 1.88 เท่า เท่านั้นเองน่ะ
แล้วจริงๆมันจำเป็นมั้ยสำหรับ Home used อย่างเราๆ ผมว่าถ้าใช้งานทั่วไปก็ไม่จำเป็นน่ะ นอกจากพวกที่ต้องการการอ่านเขียนข้อมูลเร็วๆจริงๆ เช่นทำงาน กราฟฟิก ที่ต้อง โหลดไฟล์เยอะๆ แต่ถ้ามีตังค์น่ะ ผมว่า น่าจะใช้น่ะ ผมว่าดีกว่าไปเพิ่มความเร็ว CPU อีกน่ะเพราะส่วนใหญ่ CPU ก็เร็วจนอุปกรณ์ตัวอื่นๆรอบข้างตามกันไม่ทันแล้ว แล้วตัวที่ทำงานช้าที่สุดในระบบ ก็คือ Harddisk
(ยกเว้น Floppy น่ะ) ก็ง่ายๆถ้าใครเคยใช้ H/D 5400 รอบแล้วเปลี่ยนเป็น 7200 รอบก็จะรู้ว่าเครื่องเร็วขึ้นมากๆเลย เห็นมั้ยครับ ว่าความเร็วของ Harddisk มีผลต่อระบบโดยรวมมากแค่ไหน บ่นมาก็มากแล้วเอาเป็นว่าแค่นี้ก่อนน่ะครับวันนี้…
ที่มาข้อมูลอ้างอิง : QuickPC Magazine และ PHL
เรียบเรียงบทความโดย : kirk
ขอเชิญเพื่อนสมาชิกทุกท่าน ร่วมวิจารณ์บทความนี้โดย คลิกที่นี่ครับ